Built for every industry. Trusted by global brands bringing privacy, performance, and intelligence to the edge.
Contact UsReal-time transcription that runs accurately on modern operating systems and chipsets, with no cloud dependency or metered fees and no compromise on privacy - speech-to-text that you can trust anywhere.

























































Designed for operating-system-level deployment, Sensory Speech-to-Text provides accurate, low-latency transcription entirely on the device. Multiple deployment architectures, from standard operating systems such as Android and iOS to custom solutions that run on small chipsets or in a hybrid cloud configuration, allow for you to design edge STT that works reliably even in areas with poor connectivity. This makes it easier to keep voice features persistent at the edge while using cloud selectively, not as a hard dependency. With flexible model sizes that can be under 10MB and broad language support for dozens of languages, it allows voice input even when connectivity is limited or unavailable.
Sensory STT integrates easily into local or hybrid AI systems while keeping all raw audio private by default and transferring only text to the cloud, saving orders of magnitude in bandwidth requirements. This lets you pair on-device STT with wake words, sound ID, and biometrics for fast responses on the edge, while reserving cloud and LLM capacity for tasks that require fundamental inference or dynamic content.
Sensory STT Product Brief
Designed to run efficiently where your application already lives, on the OS.


Supports mobile operating systems such as Android and iOS, “bare metal” deployments directly on small chipsets, and hybrid AI pipelines that send text off to the cloud.

Choose the right balance of accuracy, memory footprint, and CPU/GPU usage, as standalone or part of a hybrid LLM cloud system.

Supports dozens of languages with consistent accuracy across regions and accents.

No raw audio leaves the device unless explicitly configured to do so.

By transmitting compact text instead of raw audio to cloud LLMs or other services, applications reduce bandwidth use and avoid paying to stream every second of audio into metered cloud STT APIs. This lowers ongoing operating costs and keeps the system working smoothly on low‑bandwidth and spotty connections where cloud‑only approaches often struggle.

Run the same on-device speech-to-text engine across leading OSs and chipsets, avoiding single-vendor lock-in while keeping a consistent voice experience as you refresh or diversify your hardware platforms.
A simple, efficient transcription pipeline designed for OS-based systems.
By sending text instead of raw audio, applications reduce bandwidth use while keeping voice data private.

| Sensory General English Large Model (183 MB) | Word Error Rate (WER) % vs. SNR | |||||
|---|---|---|---|---|---|---|
| Test Data Set | Description | INF | 20 | 10 | 5 | 0 |
| GigaSpeech | Podcast, AudioBooks, YouTube | 14.8% | 15.3% | 17.2% | 21.4% | 34.3% |
| Common Voice | Crowd-Sourced Sentences | 11.3% | 12.4% | 15.3% | 19.9% | 32.8% |
| VoxPopuli | Parliamentary Talks (British English) | 20.9% | 21.0% | 21.2% | 23.6% | 34.9% |
| Tedlium | Oral Presentation Talks | 6.0% | 6.2% | 7.1% | 9.8% | 21.6% |
| LibriSpeech-MLS | Audio Books | 10.6% | 11.8% | 15.0% | 20.5% | 35.1% |
| LibriSpeech (test-clean) | Audio Books, Clean | 4.0% | 4.3% | 5.3% | 8.0% | 19.1% |
| LibriSpeech (test-other) | Audio Books, Noisy / Challenging | 8.1% | 9.2% | 12.0% | 17.0% | 31.4% |
Sensory speech-to-text performance in various noise conditions (INF=no noise, SNR 0=extremely loud) using commonly available test sets. Sensory provides English speech-to-text model sizes ranging from 21-183 MB, and even has some special purpose models as small as 5.3MB. There are similar model options in more than 40 languages and dialects, and models can be fine tuned for specific domains and applications.
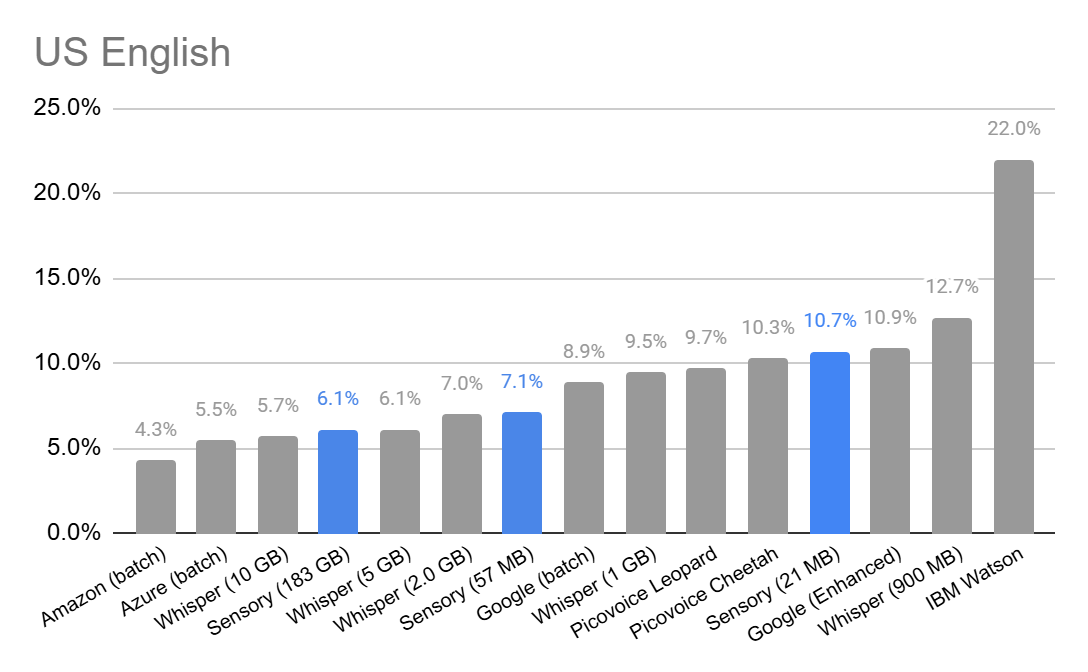
English speech-to-text model word error rates based on published data set performance results. (includes published average of test results for Librispeech test-clear, LibriSpeech test-other, TED-LIUM, and CommonVoice)
Real results. Real stories. Powered by Sensory AI.
“Sensory’s technology has exceeded our high standards for accuracy, speed, and efficiency. By enabling hands-free control of key functions through voice commands, we’re boosting productivity and streamlining workflows for retail staff. This allows our frontline workers to focus on what matters most – delivering exceptional customer service.”
“By combining MediaTek’s expertise in generative AI technology with Sensory’s strengths in on-device voice AI, the collective efforts of our companies enable significant strides in providing next-level entertainment and security in vehicles powered by MediaTek Dimensity Auto.”
“Sensory’s TrulyHandsfree technology is a key component in making the Piqo not just compact and powerful, but also incredibly user-friendly. This partnership enhances our ability to provide unmatched value and safety to our customers.”
“The smartest TV ever deserves the smartest approach to privacy. With Telly’s use of Sensory’s on-device speech-to-text and voice technologies, we are able to bring extremely fast, low-latency voice commands to the living room.”
“Zoom is passionate about making collaboration easier, but we always put our customer’s privacy and security front and center. Sensory’s technology checked all the boxes for us: accurate, fast and private…”
Interact with real-time AI demos and find out what sets us apart.
Real-world use cases for edge AI in action.
Everything You Need to Know
No. Sensory Speech-to-Text is an on-device STT engine that runs inference directly on the operating system or chipset and does not require a cloud connection for real-time transcription. This offline speech-to-text capability keeps user audio on the device by default, reduces dependency on network quality, protects user privacy, and helps you avoid recurring cloud fees at scale.
It is designed for OS-based environments and a broad range of chipsets for mobile devices, PCs, automotive, and other device-based systems, allowing you to standardize on a single on-device STT stack across product lines. Support includes Android, iOS, major desktop OSs, and “bare metal” deployments on small chipsets, which is ideal for edge platforms that are already in use throughout multiple ecosystems.
The engine supports dozens of languages, with multiple model sizes per language so you can choose the right balance of accuracy, memory footprint, and CPU/GPU usage for each device. This flexibility lets global teams deploy consistent offline speech recognition accuracy across regions, accents, and hardware tiers without rewriting their cloud integration each time.
Yes. While transcription happens on-device, you can route text output to cloud or local AI systems as part of a hybrid speech recognition architecture. This lets you keep wake words, STT, and biometrics on the edge for speed and privacy while using cloud LLMs only where they add value, such as complex reasoning or large knowledge retrieval.
Absolutely. It integrates seamlessly with Sensory’s on-device wake word, sound ID, and biometric voice solutions, enabling a complete edge AI stack from activation through transcription and verification. This approach keeps latency, privacy, and reliability under your control on the device while allowing cloud services to focus on analytics, personalization, and orchestration.
On-device STT runs directly on the device CPU, DSP, or NPU, so it avoids the network latency, packet loss, and server queuing that slow down cloud-only speech services. This local processing delivers consistent, low-latency transcription, which is especially important in automotive, industrial, and real-time assistant use cases where delays quickly degrade the user experience.
Most cloud STT services charge per minute of audio or per API call, so costs can rise quickly when you are streaming large volumes from vehicles, devices, or agents. These services are usually additive to other cloud processing. By doing STT on a device with available resources and sending only compact text to the cloud, you reduce transmission bandwidth and the consumption of cloud STT API resources, which improves cost predictability and TCO across large fleets.
Yes. Sensory Speech-to-Text is designed to provide offline speech-to-text on mobile, PC, automotive, and embedded platforms, so core interactions keep working continuously even with intermittent or no network availability. You can process commands, dictation, and safety-critical tasks locally, then selectively sync text or summaries to cloud systems when connectivity is available.
In automotive, routing every utterance to the cloud introduces variable delays that drivers notice, especially in low-coverage areas. By running STT on hardware in-vehicle, Sensory enables fast, predictable response times for navigation, media, and climate control without a network round trip, while still allowing OEMs to selectively send text to cloud or LLM services when needed.