Built for every industry. Trusted by global brands bringing privacy, performance, and intelligence to the edge.
Contact UsSecure voice authentication tied to a specific phrase, fast, private, and fully on-device.
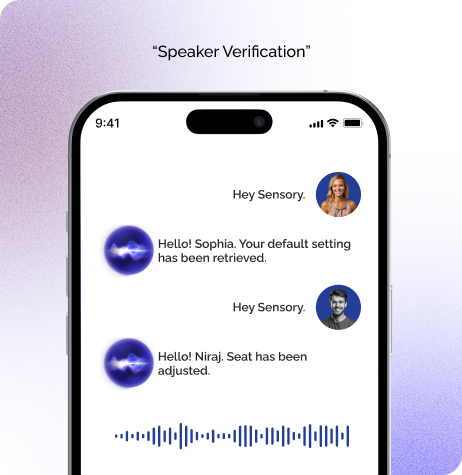

















































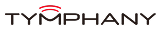







Sensory Text-Dependent Speaker Verification ties a user’s identity to a specific spoken phrase, adding repeatable, predictable security for products that require tight control. The entire process runs on-device, so the audio never leaves the hardware.
With Sensory’s two-stage verification approach, lightweight first-pass matching plus advanced neural re-validation, you get high accuracy, low power use, and immediate authentication. Ideal for personal devices, access systems, and scenarios where a fixed passphrase strengthens security.
Speaker Verification Product Brief
Purpose-built voice authentication for high-security, phrase-based verification.

Verifies identity using a specific spoken phrase. Perfect for products that require repeatable, controlled access. The user must say the same enrolled passphrase, which increases accuracy and reduces false accepts.

Low power first-pass, deep AI re-check. A lightweight model performs quick screening; if it’s likely a match, the processor wakes briefly to run advanced verification for maximum on-device security.

Nothing sent to the cloud. All audio stays local, improving privacy and reducing latency so authentication completes in under a second.

Built for real-world conditions. Optimized signal processing and noise handling allow consistent performance in cars, homes, busy rooms, or office spaces.
A simple, predictable verification pipeline that improves accuracy through fixed passphrases.
The two-stage approach delivers the best balance of security and efficiency, precise verification without constant heavy processing.

Speaker verification, also known as voice biometrics, is a technology that uses the unique characteristics of a person’s voice to verify their identity. It is a vital component for voice-based interfaces, personal assistants, and autonomous vehicles. Sensory’s speaker verification within the TSSV SDK is implemented using a novel two-stage approach for robust and accurate performance.
The first stage identifies potential matches using a lightweight statistical model.
The second stage significantly reduces false accept rates (FAs) by revalidating matches using a neural network, with only a negligible increase in false reject rates (FRs). This two-stage process yields a substantial reduction in imposter accept rate (IAR) compared to the first stage alone.
See how leading brands use Sensory’s on-device AI to deliver faster, safer, and more intuitive user experiences at scale.
“Sensory’s technology has exceeded our high standards for accuracy, speed, and efficiency. By enabling hands-free control of key functions through voice commands, we’re boosting productivity and streamlining workflows for retail staff. This allows our frontline workers to focus on what matters most – delivering exceptional customer service.”
“By combining MediaTek’s expertise in generative AI technology with Sensory’s strengths in on-device voice AI, the collective efforts of our companies enable significant strides in providing next-level entertainment and security in vehicles powered by MediaTek Dimensity Auto.”
“Sensory’s TrulyHandsfree technology is a key component in making the Piqo not just compact and powerful, but also incredibly user-friendly. This partnership enhances our ability to provide unmatched value and safety to our customers.”
“The smartest TV ever deserves the smartest approach to privacy. With Telly’s use of Sensory’s on-device speech-to-text and voice technologies, we are able to bring extremely fast, low-latency voice commands to the living room.”
“Zoom is passionate about making collaboration easier, but we always put our customer’s privacy and security front and center. Sensory’s technology checked all the boxes for us: accurate, fast and private…”
Interact with real-time AI demos and find out what sets us apart.
A phrase-based authentication system made for mobile, automotive, access control, smart devices and more.
Everything You Need to Know
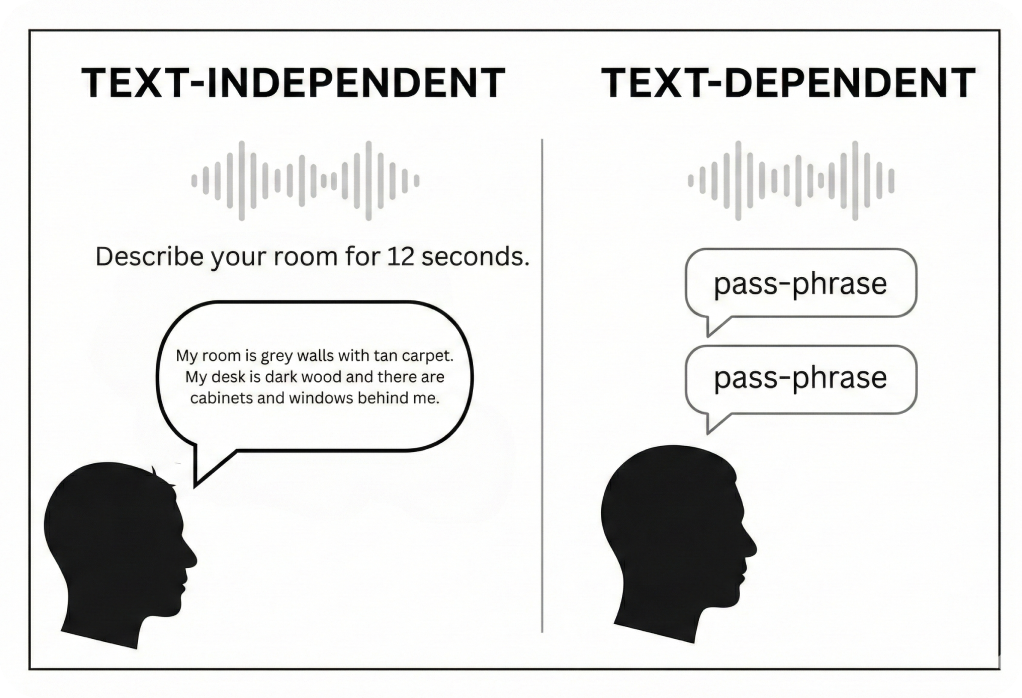
Yes, text-dependent verification requires the user to speak the exact enrolled phrase.
We recommend 3 - 4 clear repetitions to build a strong voice model.
All processing, matching, and storage happen on the device itself.
Yes, the model is optimized for noisy environments like cars and busy rooms.
Text-dependent requires a fixed phrase; text-independent verifies any spoken content.
No, the first stage is extremely low power, and the processor wakes only when needed.