Built for every industry. Trusted by global brands bringing privacy, performance, and intelligence to the edge.
Contact UsA flexible, on-device biometric engine that verifies identity from natural speech, any phrase, any wording, no script required.

























































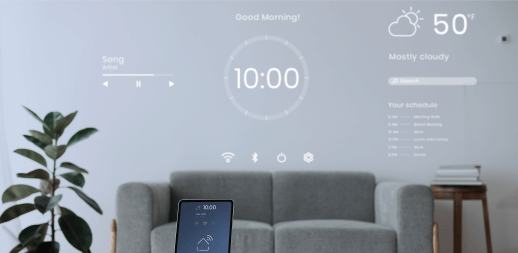
Sensory Text-Independent Speaker Verification authenticates users based on how they speak, not what they say. Instead of requiring a fixed phrase, it analyzes vocal characteristics across any natural speech. This makes it ideal for frictionless logins, continuous authentication, and hands-free verification across devices. Everything runs fully on-device, keeping biometric data private while delivering fast and reliable performance.
Speaker Verification Product Brief
Flexible voice authentication designed for natural speech and real-world conditions.


No script, no required wording.
Verifies users through natural speech for seamless experiences.

Nothing leaves the device.
All matching happens locally, ensuring privacy and quick response times.

Adaptable to your workflow.
Support login, session monitoring, or hands-free user recognition.

Built for everyday environments.
Delivers strong accuracy across accents, backgrounds, and microphone types.
Can combine with text dependent wakewords or face authentication for improved performance and increased flexibility
Identity is confirmed through vocal characteristics, not the words spoken.
Because users can speak freely, authentication feels natural and effortless—ideal for voice-controlled or conversational products.

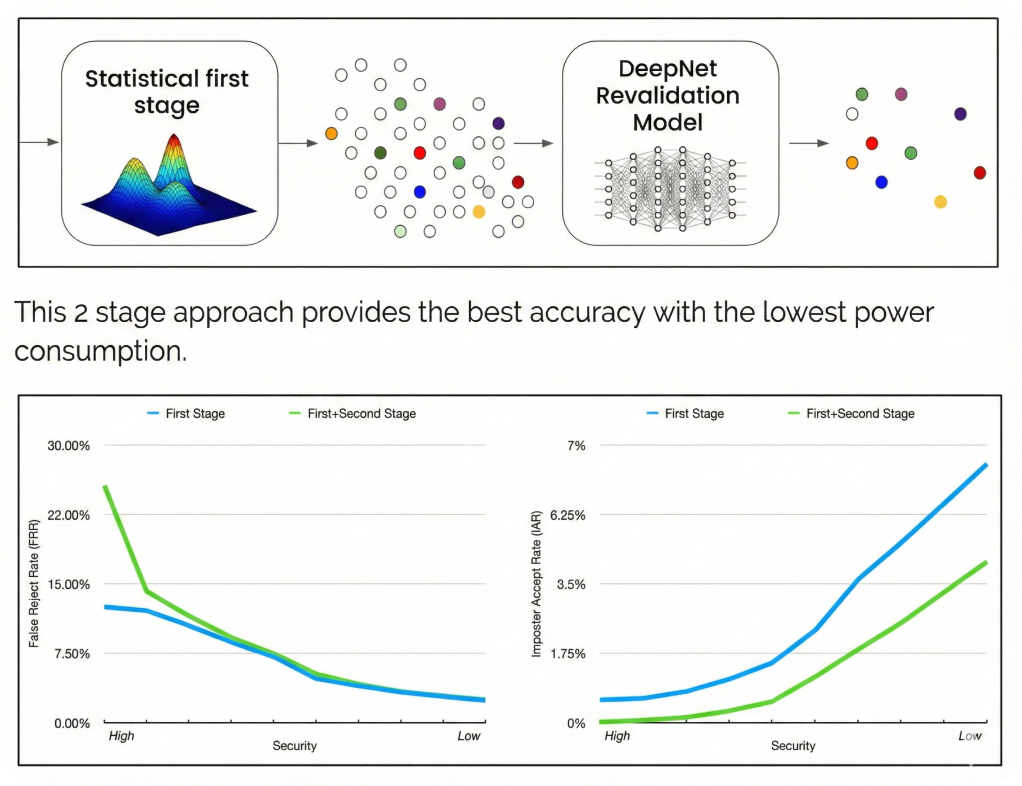
| Model | Parameter Count | Model Size | Inference Latency |
|---|---|---|---|
| Model A | 15.4M | 62 MB | 38ms per inference |
| Model B | 21.5M | 86 MB | 46ms per inference |
| Model C | 1.0M | 4.8 MB | 50ms per inference |
| Model | Parameter Count | Model Size | Inference Latency |
|---|---|---|---|
| Extra Small | 0.6M | 0.7 MB | 6ms per inference |
| Small | 1.4M | 1.4 MB | 10ms per inference |
| Medium | 2.5M | 2.5 MB | 16ms per inference |
See how leading brands use Sensory’s on-device AI to deliver faster, safer, and more intuitive user experiences at scale.
“Sensory’s technology has exceeded our high standards for accuracy, speed, and efficiency. By enabling hands-free control of key functions through voice commands, we’re boosting productivity and streamlining workflows for retail staff. This allows our frontline workers to focus on what matters most – delivering exceptional customer service.”
“By combining MediaTek’s expertise in generative AI technology with Sensory’s strengths in on-device voice AI, the collective efforts of our companies enable significant strides in providing next-level entertainment and security in vehicles powered by MediaTek Dimensity Auto.”
“Zoom is passionate about making collaboration easier, but we always put our customer’s privacy and security front and center. Sensory’s technology checked all the boxes for us: accurate, fast and private…”
“Sensory’s TrulyHandsfree technology is a key component in making the Piqo not just compact and powerful, but also incredibly user-friendly. This partnership enhances our ability to provide unmatched value and safety to our customers.”
“The smartest TV ever deserves the smartest approach to privacy. With Telly’s use of Sensory’s on-device speech-to-text and voice technologies, we are able to bring extremely fast, low-latency voice commands to the living room.”
Interact with real-time AI demos and find out what sets us apart.
Identity verification through free-form speech, built for mobile, automotive, smart devices, and more.
Everything You Need to Know
Text-independent systems don’t require a specific phrase. They authenticate based on the speaker’s voice itself.
No. The system can verify identity from short phrases, commands, or brief conversational snippets.
Yes. All biometric matching happens locally, ensuring privacy and reducing latency.
Yes. The model is optimized for embedded systems and low-power devices.
Absolutely. TISV can verify users throughout a session using natural speech.
The model is built for real-world use and handles typical background noise effectively.