Built for every industry. Trusted by global brands bringing privacy, performance, and intelligence to the edge.
Contact Us
A serial entrepreneur with an IPO, an acquisition, 50+ patents, and a lifetime in audio-tech innovation. Todd has deep experience licensing and working with the largest tech companies in the world, including Amazon, Apple, Google, Microsoft, Samsung, and many others.

See how Sensory technology transforms user experiences — instantly, privately, and securely.


Sensory’s embedded voice AI consistently outperforms competitors in independent benchmarks, achieving 50% lower error rates than Picovoice (4.7% vs 10% WER), beating Amazon’s cloud STT accuracy (4.7% vs 5.2% WER), and delivering production-grade performance that open-source alternatives like OpenWakeWord cannot match.
The demand for on-device voice AI is exploding as product teams realize the hidden costs of the cloud: latency, recurring SaaS fees, and massive privacy concerns. But when you move voice processing to the edge, the margin for error shrinks. You need extreme accuracy within strict memory and compute budgets.
Today, the competitive landscape for embedded Key Word Spotting (KWS) and Speech-to-Text (STT) is crowded. You have legacy solutions like Sensory, Cerence, SoundHound, and Picovoice, plus a raft of new startups wrapping open-source models.
So, how does Sensory’s Key Word Spotting for wakewords/hotwords and small command sets and Sensory’s Speech-to-Text stack up against the rest? Let’s look at the data.
The Holy Grail of Wakewords: Low False Rejects, Zero False Alarms
A wake word is the front door to your product’s user experience. If it fails to open (False Reject or FR) or opens when no one is there (False Accept or FA), user trust evaporates, frustration emerges and privacy can be lost.
To see how Sensory compares with wakewords and small command sets by other vendors, we can look at an independent benchmark conducted by Vocalize.ai. Vocalize.ai is an independent test house that was used by companies like Sensory and Google, and Sensory decided to acquire and use them for rigorous internal and third-party benchmarking. Results shown here are from the time when Vocalize was completely independent. Vocalize tested commercially available wake word models with the same noise conditions (Silence, Pink Noise, Babble, and Music) and true wakeword recordings. None of the models were trained on the test data. FA rates were normalized to be the same as or very similar to Amazon.
Vocalize.ai Wakeword (Alexa) Accuracy in Background Noise (False Reject Rate)
| Noise Condition | Sensory (1MB) | Sensory (250KB) | Amazon (250KB) | Snowboy / Open Source (2MB) |
|---|---|---|---|---|
| Silence | 0% | 0% | 3% | 5% |
| Pink Noise | 8% | 13% | 15% | 58% |
| Babble | 0% | 3% | 10% | 18% |
| Music | 5% | 8% | 13% | 45% |
Data Source: Vocalize.ai Competitive Performance Evaluation. Lower is better.
Sensory’s 1MB and 250KB models consistently outperformed both Amazon’s edge offering and KITT.AI’s Snowboy (a previously popular open-source derivative) across all noise environments. Furthermore, in a separate Vocalize.ai test measuring end-to-end Task Completion Rate (TCR) for small commands in a microwave domain, Sensory’s embedded large vocabulary domain specific engine achieved a 93% success rate, crushing Amazon Alexa’s 55%. Since that time, Sensory’s technology has only gotten better. Full reports are available on request.
The Open-Source Challenge
With the explosive growth of TinyML, many startups are attempting to build products using open-source tools. A current community favorite is OpenWakeWord, but there are dozens of startups emerging selling approaches based on open source, and all have similar issues.
While open-source offers incredible flexibility for hobbyists and DIY smart home builders, it often falls short of commercial-grade requirements. In Sensory’s testing of OpenWakeWord, we found outdated scripts, unmaintained repositories, and dependency mismatches, plus a need for substantive data and tuning expertise. It’s no wonder that many of the companies that fight through these challenges start to sell their own home-made solutions based on the open source they used.
More importantly, community testing shows that while open-source models can eventually reach a baseline accuracy, they are not State-of-the-Art (SOTA). They struggle with multi-lingual support, lack deep microcontroller optimization, and suffer from high False Accept rates in real-world noisy environments—fatal flaws for consumer hardware.
The result of Sensory’s in-house comparison is shown here using a difficult wakeword – “stop” – a single syllable but with reasonable phonetic content. It’s worth noting that performance varies widely with the wakeword selection, usage environment, model sizes, front end noise strategies and signal to noise ratio:
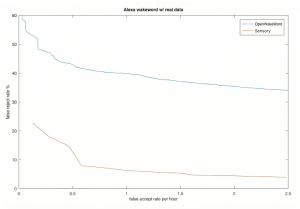
This test was done in identical noise settings with identical test data. Sensory used its VoiceHub tool (fully automated model developer with no manual tuning and no live data recordings required) and OpenWakeWord was done with minimal tunings and recordings. The results show that Sensory can reach lower FR error rates that are not possible with open source and can be an order of magnitude better in performance.
What about Challenging Wakewords with Stringent Test Requirements?
With carefully crafted data collection and expert tuning, Sensory can optimize for accuracy and size and pass the most stringent tests across many languages, while few competitors could pass them in even one.
The most challenging wake-word Sensory has ever developed for commercial deployment (and we have more wake-word experience than any company in the world!) is the “Enhanced Siri” requirement from Apple. This is used in automotive environments where the expectation is to be able to say “Siri” without the “Hey” and still achieve Apple’s stringent FA and FR requirements. Sensory has passed Apple’s Enhanced Siri test in more languages than any company. Here are recent benchmarks on a specific automotive platform (performance can vary with platform specifications):
| “Siri” Language/Accent | Condition | False Reject (FR) | False Accept (FA) 2hr drive | Pass/Fail |
| US English | 21dBA | 2.33% | 0.02 | Pass |
| US English | Quiet | 0.22% | 0.24 | Pass |
| UK English | Quiet | 1.61% | 0.14 | Pass |
| German | Quiet | 1.19% | 0.44 | Pass |
| Mandarin (Mainland China) | Quiet | 1.75% | 0.22 | Pass |
| Spanish (Mexico) | Quiet | 0.08% | 0.24 | Pass |
| Japanese | Quiet | 0.06% | 0.32 | Pass |
| Portuguese (Brazil) | Quiet | 0.86% | 0.22 | Pass |
| Dutch test | Quiet | 2.83% | 0.08 | Pass |
| Arabic | Quiet | 1.35% | 0.40 | Pass |
| French (Canada) | Quiet | 1.90% | 0.14 | Pass |
| Italian | Quiet | 1.25% | 0.40 | Pass |
| English (Australian) | Quiet | 1.45% | 0.24 | Pass |
| Spanish (Spain) | Quiet | 0.14% | 0.38 | Pass |
| Thai | Quiet | 0.77% | 0.40 | Pass |
| Czech | Quiet | 0.46% | 0.32 | Pass |
| Spanish (US) | Quiet | 0.77% | 0.40 | Pass |
| Hungarian | Quiet | 0.22% | 0.30 | Pass |
These results show the effect of a carefully tuned wakeword that is extremely challenging. For less challenging wakewords Sensory’s tool suite includes VoiceHub to create models quickly and inexpensively using synthesized data and automated tuning. A well selected VoiceHub model with unique sounds and many syllables can achieve <5% FR rate with only 1 FA every week in normal usage settings…and VoiceHub can do this across dozens of deployment platforms and over 20 languages.
Speech-to-Text (STT) on the Edge: The Picovoice Analysis
When moving beyond simple commands to full Speech-to-Text dictation, the goal is to match cloud-level accuracy, but without the cloud.
To evaluate this objectively, we want to give credit to Picovoice. They were willing to publish a highly transparent, open-source ASR benchmarking framework designed to compare edge and cloud engines across standard pristine datasets like LibriSpeech, Tedlium, and CommonVoice.
Using Picovoice’s own benchmark framework and results to evaluate Word Error Rate (WER), Sensory was able to benchmark and compare its embedded STT to the same cloud giants and embedded competitors:
STT Word Error Rate (WER) Comparison
| STT Engine | Average WER | Model Size | Deployment |
|---|---|---|---|
| Sensory STT Large | 4.7% | ~195 MB | Edge |
| Amazon | 5.2% | N/A | Cloud |
| Whisper (Large) | 5.7% | 2944 MB | Edge |
| Sensory STT Small | 8.5% | 24 MB | Edge |
| Whisper (Base) | 9.5% | 139 MB | Edge |
| Picovoice Leopard | 10.0% | 36 MB | Edge |
| Picovoice Cheetah | 10.7% | 31 MB | Edge |
Data Source: Internal tests leveraging Picovoice’s open-source speech-to-text benchmark methodology. Lower WER is better.
The results speak for themselves. Sensory’s edge model not only achieves an incredibly low 4.7% WER, but it also beats Amazon’s cloud engine and OpenAI’s massive 3GB Whisper Large model. When compared directly to Picovoice’s on-device solutions (Leopard and Cheetah), Sensory can cut the error rate in half with a larger edge model and still outperform Picovoice by 20% with a much smaller model size.
What About Cerence, SoundHound, and others?
Cerence and SoundHound have built impressive, deep domain-specific voice assistants, particularly in the automotive sector. We don’t have access to data to perform benchmarks, but customers consistently tell us Sensory outperforms in wakewords in general, and especially when smaller size matters. We have replaced entrenched competitor solutions for STT by running better performance on device while also saving our OEMs recurring cloud fees! Sensory keyword spotting is used by companies such as Google, Amazon, Apple, Huawei, Samsung, Microsoft and others and is a testimony to Sensory’s performance in small footprint command sets.
Many competitors are heavily tied to cloud or hybrid architectures and often demand massive custom engineering efforts, high upfront NRE costs, or ongoing cloud fees. Sensory’s differentiator is delivering SOTA performance strictly on the edge.
The Bottom Line
If you are building an edge device, you shouldn’t have to compromise. Open-source wrappers take a large team investment to implement accurately and are often too fragile for production. Picovoice sacrifices too much accuracy for its size, and legacy enterprise systems are too heavy and expensive over time. Sensory remains in the sweet spot of the features that matter – proven, low power, low heat, ultra-accurate, private, cost-effective and deeply embedded.
 Todd Mozer
Todd Mozer
Custom wake words have become one of the fastest, lowest-friction ways to turn a generic voice interface...