Built for every industry. Trusted by global brands bringing privacy, performance, and intelligence to the edge.
Contact UsVoiceHub gives you an easy way to design and deploy high-accuracy vocabularies with your choice of size, platform, and language.













VoiceHub is Sensory’s self-service platform for building custom wake words and word-spotted commands. It gives developers a fast, intuitive way to create and iterate on speech models without needing deep ML experience or custom data collection.
With support for multiple chip architectures, flexible model sizes, and dozens of languages, VoiceHub helps teams deliver reliable, on-device voice experiences that work in real-world noise saving time, cost, and privacy.
Request the Wake Word Selection Checklist!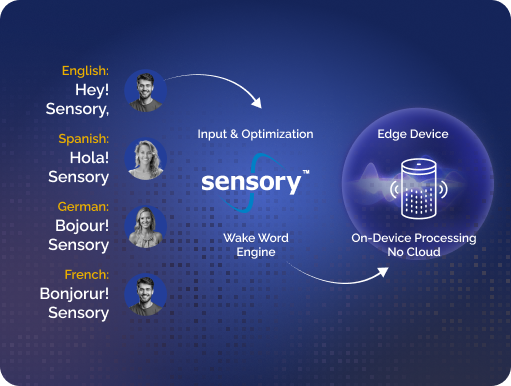
A simple, powerful workflow for creating embedded speech models.


Create wake words and command sets through a simple interface, no ML background required.

Choose from multiple footprints optimized for your device’s available power, memory, and compute.

Models are trained using Sensory’s embedded neural networks for accuracy in noisy environments.

Build for global users with models available in dozens of languages.
All of this uses a no‑code GUI that handles the model architecture, synthetic data generation, and training pipeline behind the scenes.
Click here for a full step‑by‑step VoiceHub tutorial.

Check out a webinar featuring Panasonic Automotive for a live demo!
See how leading brands use Sensory’s on-device AI to deliver faster, safer, and more intuitive user experiences at scale.
“The smartest TV ever deserves the smartest approach to privacy. With Telly’s use of Sensory’s on-device speech-to-text and voice technologies, we are able to bring extremely fast, low-latency voice commands to the living room.”
“Sensory’s TrulyHandsfree technology is a key component in making the Piqo not just compact and powerful, but also incredibly user-friendly. This partnership enhances our ability to provide unmatched value and safety to our customers.”

“Zoom is passionate about making collaboration easier, but we always put our customer’s privacy and security front and center. Sensory’s technology checked all the boxes for us: accurate, fast and private…”

“Sensory’s technology has exceeded our high standards for accuracy, speed, and efficiency. By enabling hands-free control of key functions through voice commands, we’re boosting productivity and streamlining workflows for retail staff. This allows our frontline workers to focus on what matters most – delivering exceptional customer service.”
“By combining MediaTek’s expertise in generative AI technology with Sensory’s strengths in on-device voice AI, the collective efforts of our companies enable significant strides in providing next-level entertainment and security in vehicles powered by MediaTek Dimensity Auto.”
Interact with real-time AI demos and find out what sets us apart.
VoiceHub models scale across industries and languages, adapting to your device’s memory, power, and compute limits while maintaining consistent on-device performance.
Everything You Need to Know
VoiceHub is for anyone who needs custom wake words or command sets without deep machine learning expertise, including embedded engineers, UX teams, and system integrators.
Yes. VoiceHub outputs embedded-quality models derived from the same technologies Sensory ships at scale, and many customers move from VoiceHub prototypes into production with appropriate validation and integration.
VoiceHub supports multiple builds optimized for different footprints and architectures, including MCUs and DSPs from major silicon partners; you can export the format that best fits your chip and reference designs.
No. Once deployed, VoiceHub models run fully on-device, so wake words and commands work offline and maintain privacy even in low‑connectivity environments.
Yes. You can create multilingual models and deploy across global product lines using the same portal, selecting languages and dialects per project.